PROJECT NAME:
Aurai Framework
SHORT DESCRIPTION:
Aurai is an small game framework aimed to learn about DirectX12. It features Forward, Forward+, Tiled Deferred and Deferred rendering.
ENGINE/LANGUAGES/FRAMEWORKS:
Custom Framework (C++), DirectX12.
DATE:
September 2017 – February 2018

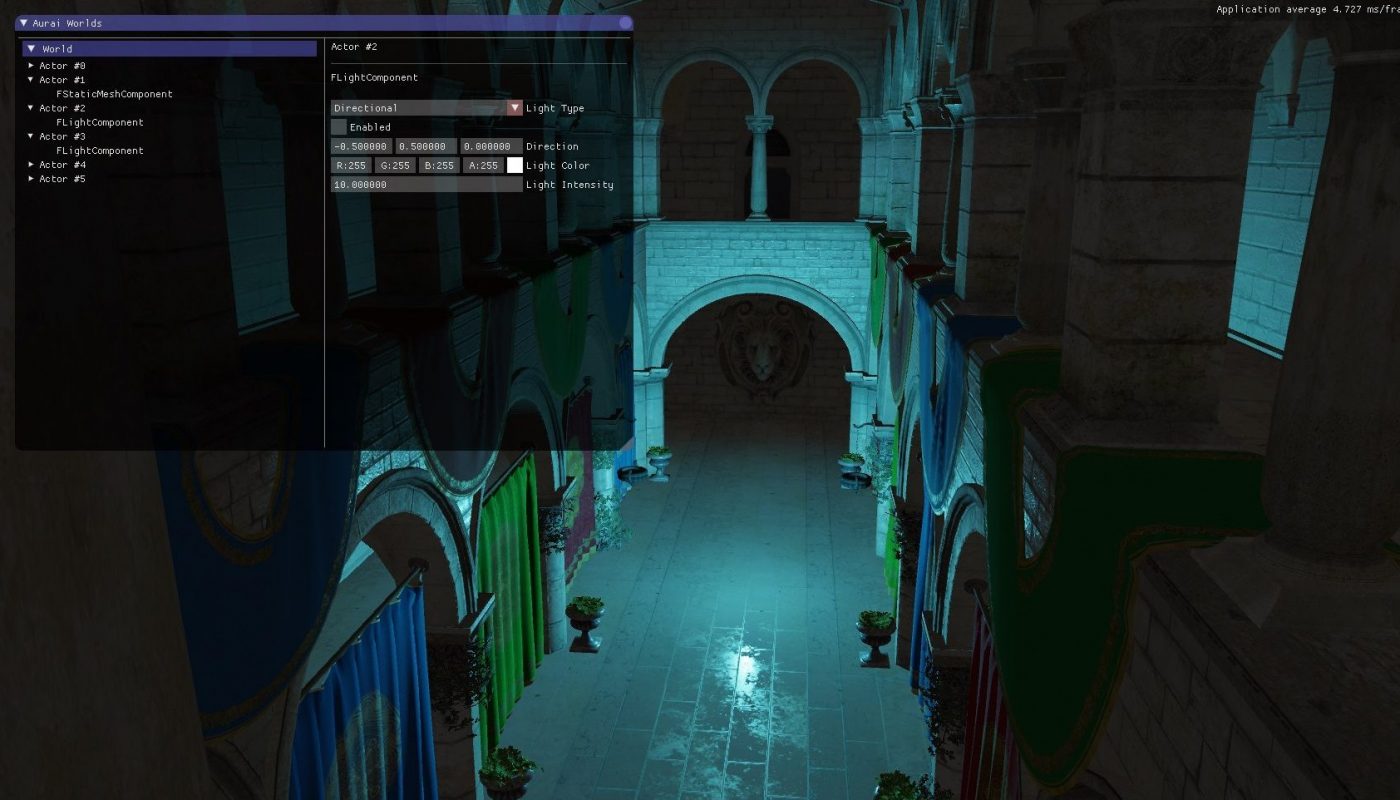

Project Details
Prior to working on this project, I had little to no experience working with graphics API’s (Only OpenGL 4.5 for a 2D space RTS). I was interested in learning more about graphics and 3D rendering. I wanted to challenge myself a little bit so I decided to learn DirectX12 and use it to render a scene and write some visual effects and learn multiple ways of optimizing lighting calculations.
Features
Tiled Rendering
 I implemented multiple techniques of rendering geometry to test what their benefits and drawbacks are.
I started with implementing the easiest technique which is forward rendering. With forward rendering you directly do the lighting calculations while drawing an object, however, if there is much overdraw there are a lot of resources wasted in performing lighting calculations for pixels that get discarded. This is where deferred rendering aims to improve. Deferred rendering first draws the base color and other data such as normals into a collection of textures; this is called the G-Buffer. Once these textures are rendered, their information will be used to do lighting calculations which guarantees only performing lighting calculations once per pixel. Even though we have to perform lighting once per pixel with deferred, having many lights in the scene will still perform slowly because a lot of pixels have to perform lighting calculations even if that light does not influence that pixel. By splitting up the screen into tiles (usually 32*32 or 64*64 pixels) and calculating which lights affect that tile we can only have to do lighting calculations for lights that most likely affect those pixels, greatly improving performance.
I implemented multiple techniques of rendering geometry to test what their benefits and drawbacks are.
I started with implementing the easiest technique which is forward rendering. With forward rendering you directly do the lighting calculations while drawing an object, however, if there is much overdraw there are a lot of resources wasted in performing lighting calculations for pixels that get discarded. This is where deferred rendering aims to improve. Deferred rendering first draws the base color and other data such as normals into a collection of textures; this is called the G-Buffer. Once these textures are rendered, their information will be used to do lighting calculations which guarantees only performing lighting calculations once per pixel. Even though we have to perform lighting once per pixel with deferred, having many lights in the scene will still perform slowly because a lot of pixels have to perform lighting calculations even if that light does not influence that pixel. By splitting up the screen into tiles (usually 32*32 or 64*64 pixels) and calculating which lights affect that tile we can only have to do lighting calculations for lights that most likely affect those pixels, greatly improving performance.